Setting the type of indicator and how it will be measured
Click on an indicator in the logframe to see the Indicator detail window at the bottom of your screen. The content of this window depends on the type of indicator (the question type). On top you can see the Indicator toolbar, with the text of the indicator repeated in bold underneath. On the next line, you can choose to which target group this indicator applies. Finally on the bottom there is a table where you can design the details of your indicator.
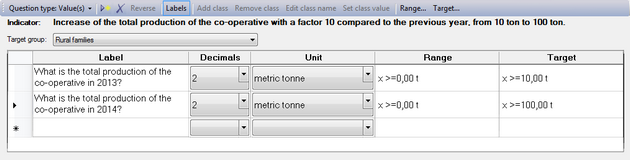
This table at the bottom allows you to work with compound indicators, or indicators that are made up of a series of questions that bring together the information you're looking for. Alternatively, you can also specify different targets for different years - as in the example above.
If you want a simple indicator, you can just fill in the first line of the table.
The Indicator toolbar

Basic functions:
- To change the type of question/indicator, use the
 button in the toolbar.
button in the toolbar. - To add a response to the table, you can click on the
 button in the toolbar. Alternatively, you can simply go to the bottom row of the table and enter your text there.
button in the toolbar. Alternatively, you can simply go to the bottom row of the table and enter your text there. - To remove a response from the table, click on the
 button in the toolbar.
button in the toolbar. - You can show or hide the labels column(s) by clicking the
 button.
button. - For certain types of indicators, you can add responses in the form of columns (for instance for a multiple choice question). These options are referred to as classes and there are three buttons to manipulate them:
- The Add class button
- The Edit class button
- The Remove class button
- The Add class button
- When you work with values (or percentages), you can limit the range of values that people can use, using the
 button.
button. - For many types of indicators, you can indicate the
 range , either as values or percentages, or else as a part of the population (also in percentages).
range , either as values or percentages, or else as a part of the population (also in percentages).
Question types
Logframer allows you to choose from a whole range of indicator types:
- The open ended question
- Registration of values or percentages
- Multiple choice questions, multiple options questions
- Yes/no-questions
- Ranking questions
- Best/worst scaling (maximum differential)
- Preferential scales where the respondent has to indicate his preference on a number of options: Thurstone scale, Summative scale (Likert), Cumulative scale (Guttman)
- Semantic differential
Open-ended questions
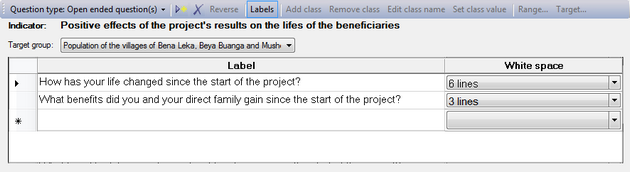
The advantage of an open-ended question is that it allows people to express themselves freely, thus providing you with information that you might not have found otherwise. Open-ended questions are also interesting to get information about how a person feels about something. Often, the answers you get are more objective than direct or closed-ended questions.
Typically, open-ended questions start with 'Why...', 'How...', 'How do you feel about...' and so on.
The disadvantage of open-ended questions is that by definition, the replies are not standardised. This means that collecting, treating and analysing the information can be more complex, especially when you interview a lot of people.
In terms of the logical framework, open-ended questions are interesting to measure outcomes (expected or unexpected effects; wanted or unwanted effects) and impact (expected or unexpected; wanted or unwanted).
You can enter one or more questions in the 'Label' column of the table. In the 'White space' column you can set how much space the respondent or the interviewer has to note down the answer. This way you have some measure of control to the length of the answer. The amount of white space can vary from 1 to 7 lines, or from a quarter page to a full page.
Registration of values or percentages
In many cases, you will want to register hard data in the form of absolute values. Often, Objectively Verifiable Indicators are seen as synonymous to numbers, however this needn't be the case. Also take into account that numeric indicators may look good on paper, but may be very difficult to measure in practice. In many countries, statistics are notoriously hard to get by, and people are far less 'number-oriented' than in highly developed societies, where everything is measured and everything has got a price.
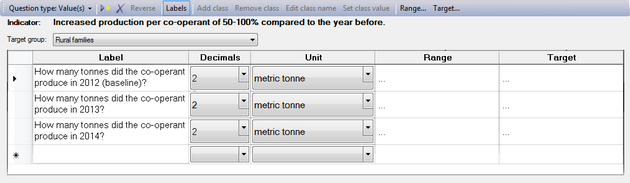
- In the 'Label' column, you can specify your question(s).
- The 'Decimals' column allows you to specify to what degree of exactitude the value has to be measured, i.e. the number of decimals behind the decimal point/comma.
- You can specify the unit of your values using the drop-down list of the Unit column. You can choose from a wide range of metric units, US customary units, time units and others. If you can't find the unit you need, simply type it into the field and it will be added to the list as a user-defined unit.
Setting a range
If you want to set a limit to the values that should be registered, you can identify a range. When you click on the button, you will get a pop-up dialog that allows you to set the bottom value and top value of the range. You can also double-click on the cell to open this dialog window.
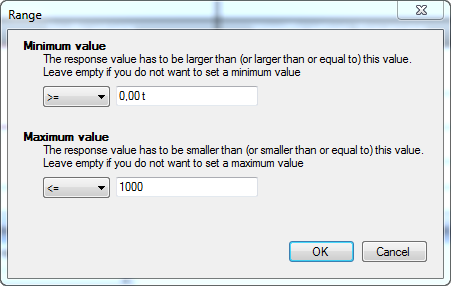
The drop-down list on the left of the value field allows you to specify whether the registered value has to be greater than, greater than or equal to, or equal to the minimum value. For the maximum value, you can set whether the value has to be smaller than, smaller than or equal to, or equal to this value.
You do not need to set both the minimum and maximum value. For instance, if you want to avoid negative values, you can set the minimum value to greater than or equal to zero.
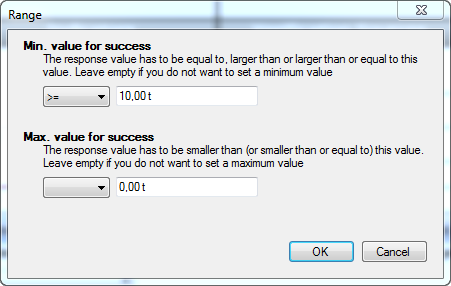
Setting a target
More often than not, you'll have a target to achieve. By clicking on the button, or double-clicking on the target cell in the table, you will get a similar dialog to the one used for setting the range.
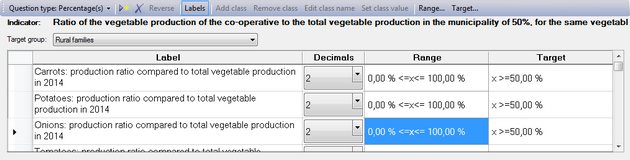
Percentage values
If you select 'Percentage' as the question type, you get almost exactly the same window. The difference is that there is no Units column, and that all values are expressed as a percentage.
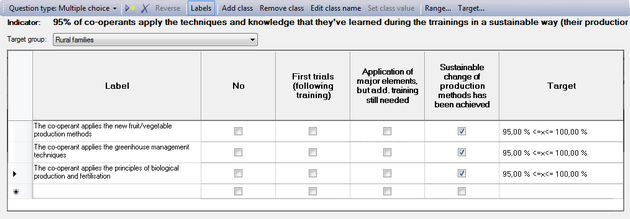
Multiple choice / multiple options
Multiple choice and multiple options questions allow you to identify a series of standard responses from which your respondent or interviewer/observer can choose from. With multiple choice, you can only select only one of the options. With multiple options, you can select more than one option at a time.
Working with classes
Modifying the class names (column headers)
When you set the Question type to 'Multiple choice', you will get an empty table with three classes, called 'Class 1', 'Class 2' and 'Class 3'. To change these column headers, just click somewhere in the column, and then on the button. You can also double-click on the column header. This will make a text field appear, where you can modify the name of this class (column).

Adding and removing classes
If you want to add a class (column), click in the column to the right of where you want to insert it. For instance in the example above, if you want to add a column between Class 2 and Class 3, you should click in the Class 3 column. Then press the button in the toolbar.
If you want to remove a class (column), click in the column itself and then on the button.
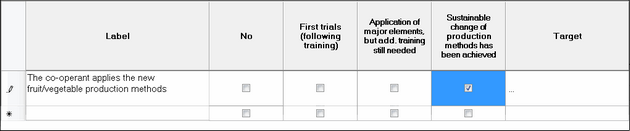
Add questions and indicate the preferential answer
Go to the first row and enter the first question in the 'Label' column. Then you can indicate what would be the correct or preferred answer from your respondents, by clicking in that column. A check mark will appear.
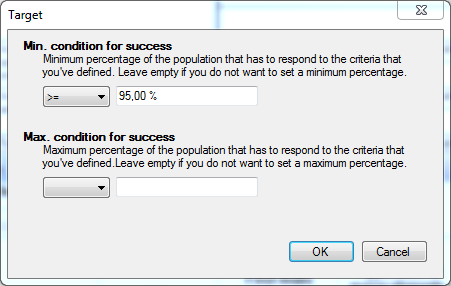
Setting the target of a multiple choice/options question
You can set the target in terms of how many beneficiaries out of the total group (population) will achieve this target. Click on the button, or double-click on the target cell in the table to open the following dialog window:
Setting class values
If you want, you can give every class a number to facilitate the registration of results. You can use these values in a different way too, to give points or scores as in the example below: if the co-operant has only introduced some elements of what he/she learned on a training, he/she will get 1 or 2. If she/he rely applies what she/he has learned, then the score will be 3 or 4.
Click on the 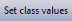 button to open the following dialog:
button to open the following dialog:
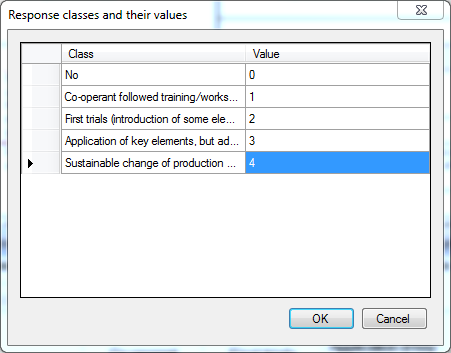
In the first column, you can see the class names (the text that appears in the column headers). In the second column you can enter any value you want.
When you press the < OK > button, you will see these values appear in the column headers between brackets, below the text, as in this example:
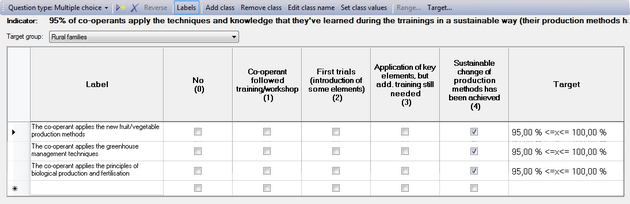
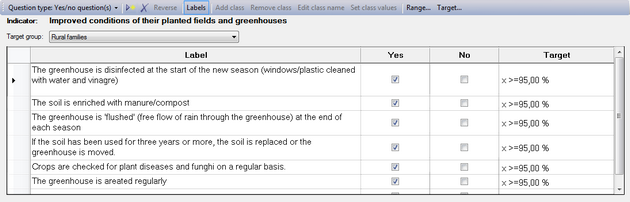
Yes/No questions
Some questions can be answered by a simple yes or no. This type of question is easy to use, and a series of yes/no questions can be used to measure more complicated indicators. For each question, you can indicate the correct answer, and you can also set a target in terms of what percentage of the population should get it right.
Add questions and indicate the preferential answer
Go to the first row and enter the first question in the 'Label' column. Then you can indicate what would be the correct or preferred answer from your respondents, by clicking in that column. A check mark will appear.
Set the target
You can set the target in terms of how many beneficiaries out of the total group (population) will achieve this target. Click on the button, or double-click on the target cell in the table to open the following dialog window:
Ranking questions
With ranking questions, you present the respondent with a number of options, and ask him or her to indicate which one is the most important, second most important, third most important (and so on).

Working with classes
Modifying the class names (column headers)
When you set the Question type to 'Ranking', you will get an empty table with three classes, called 'Class 1', 'Class 2' and 'Class 3'. To change these column headers, just click somewhere in the column, and then on the button. You can also double-click on the column header. This will make a text field appear, where you can modify the name of this class (column).
Adding and removing classes
If you want to add a class (column), click in the column to the right of where you want to insert it. Then press the button in the toolbar.
If you want to remove a class (column), click in the column itself and then on the button.
Add questions and indicate your preferential ranking
To add questions, go to the first row and enter the questions in the 'Label' column.
If you want, you can indicate the preferential ranking, meaning the ranking that you hope to achieve by the end of the project (or any other period of time). For instance, in the example below, most people sell their produce immediately when it's harvested. This means that often they don't get a good price, because at harvest time there are a lot of producers offering their vegetables and so on at the same time, so prices are low. It would be better to sell them when there aren't many vegetables around, but that means you have to keep them in a warehouse or freezer. Another option to add value is to transform them into something that has more value (soup or sauce or canned vegetables...)
So when we ask the producers before the project starts what the most important source of income is, they may rank it as follows:
- Selling of vegetables directly from the field/greenhouse
- Selling of transformed produce
- Selling of produce that has remained in the warehouse until prices are higher
What you hope to see in the end is that a certain percentage of producers have changed this order around to:
- Selling of produce that has remained in the warehouse until prices are higher
- Selling of vegetables directly from the field/greenhouse
- Selling of transformed produce
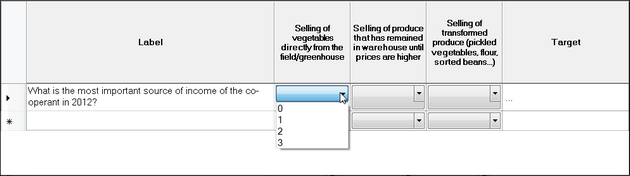
To set the preferential ranking, just click on the drop-down list and select any of the values. You can also click on the cell and type the value. The minimum value is zero, the maximum value is equal to the number of classes (columns).
Set the target of a ranking question
You can set the target in terms of how many beneficiaries out of the total group (population) will achieve this target. Click on the button, or double-click on the target cell in the table to open the following dialog window:
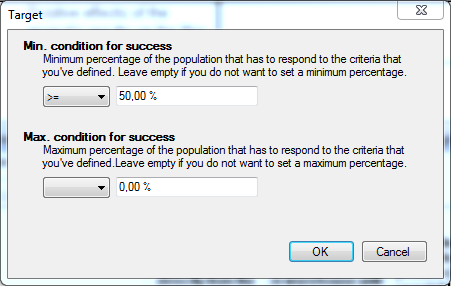
You can set out a preferential ranking that you would like to achieve by the end of the project, and indicate per year how your beneficiaries will evolve towards that target, as in the example below:

Best/worst scaling or MaxDiff scales
When you use best/worst scaling or MaxDiff scaling (Maximum differential), you present the respondent with a number of options. Then you ask him or her to indicate which one in his/her opinion is the most important (or the best), and which on is the least important (or the worst).
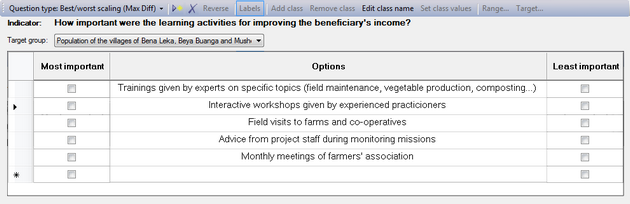
Compared to other rating scales, best/worst scaling pushes people to make a clear-cut choice between a number of options. Instead of asking people to choose the best out of one pair and then move on to the next pair and the next until you've got a definite choice, this kind of scaling allows the respondents to choose directly from a whole set, which makes it easier to use and to take a decision. Another benefit from MaxDiff scaling is that there are no numbers involved, people just have to indicate the best and the worst choice in their opinions.
Modifying the class names (column headers)
When you set the Question type to 'Best/worst scaling (MaxDiff)', you will get an empty table with an Options column in the middle, with a check box column on either side. By default, Logframer will indicate the column on the left 'Most important' and the one on the right with 'Least important'.
You can change the headers of these columns any way you want. To do this, click somewhere in the column, and then on the button. You can also double-click on the column header itself. This will make a text field appear, where you can modify the header of this column.
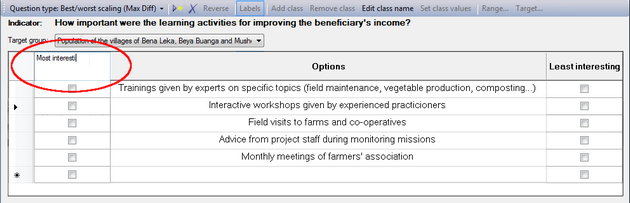
Add questions and indicate your preferential ranking
To add questions, click in an empty cell in the 'Options' column in the middle and enter your text.
If you want, you can also indicate the preferential ranking, for one or both selection columns, to indicate the ranking that you hope to achieve by the end of the project (or any other period of time).

Thurstone scale (method of equal-appearing intervals)
The method of equal-appearing intervals or the Thurstone scale is used to measure attitudes of people. Logframer allows you to use a Thurstone scale to measure an indicator, but developing such a scale is not so simple.
This kind of scale is used to measure people's attitude towards a fairly clear and unidimensional concept, using a number of statements that vary in how they express a positive or negative opinion about the main concept. We'll briefly explain the steps of developing a Thurstone scale:
- Determine the focus: what concept are you going to measure (see what people's attitudes are toward it)?
- Ask a group of people (or a person) to write down different statements about this concept, reflecting different opinions or attitudes about the subject. Make sure you have a large number of statements, making sure that people can either degree or disagree with them (no - open - questions for instance).
- Rating the scale items: the next step is to have your group rate each statement on a 1-to-11 scale in terms of how much each statement indicates a favourable attitude towards the concept. The members of the group must not express their own opinion, they must only indicate how favourable they feel each statement is. You can use a scale with 1 = extremely favourable attitude towards the subject (focus) and 11 = extremely unfavourable attitude towards the subject.
- Compute the median and interquartile range for each statement. Create a table with these values and sort by the median.
- Select the items for the actual scale: you should select statements that are at equal intervals across the range of medians. Within each value, you should try to select the statement that has the smallest Interquartile Range. This is the statement with the least amount of variability across judges. You don't want the statistical analysis to be the only deciding factor here. Look over the candidate statements at each level and select the statement that makes the most sense. If you find that the best statistical choice is a confusing statement, select the next best choice.
For a detailed example, see http://www.socialresearchmethods.net/kb/scalthur.php
You can now use the scale to measure attitudes 'in the field': enter the list of statements and use them to interview people or present them in a document. For each item, they should express whether they agree or disagree. The total score of a person is calculated by making the sum of the values of all the statements they agreed with, divided by the number of items he agreed on (in other words, the average of the statements they agreed with).
Modifying the class names (column headers)
When you set the Question type to 'Scale (Thurstone)', you will get an empty table with the usual 'Labels' column, and two classes: 'Agree' and 'Disagree'. You can change the headers of these columns any way you want, but make sure that the second column remains the favourable option and the last column the unfavourable option.
To change the column headers, click somewhere in the column, and then on the button. You can also double-click on the column header itself. This will make a text field appear, where you can modify the header of this column.
Add statements
To add the statements that make up your scale, go to the first row and enter them in the 'Label' column.
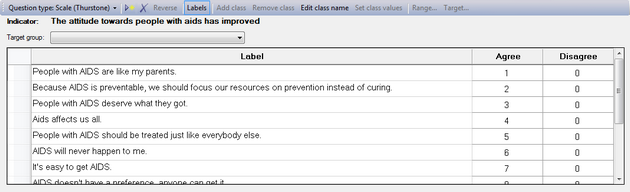
Every time you add a statement, you will see a value appear in the 'Agree' column (second column). The first statement will get 1, the second 2 and so on. In other words, Logframer assumes that the first statement is the first one on your scale and so on. But if you want to randomize your statements and use different values than the ones that are generated automatically you can do so.
Modifying the values of the favourable answers ('Agree' column)
If you want to change the values that are automatically inserted when you add a new statement, just click on the cell and type another value of your scale. You can only modify the 'Agree' column, not the 'Disagree' column.

Likert scale (summative scale)
The Likert scale can also be used to measure attitudes of people. When responding to a Likert questionnaire item, respondents specify their level of agreement or disagreement on a symmetric agree-disagree scale for a series of statements. Thus, the range captures the intensity of their feelings for a given item. As with the Thurstone scale, the development of a Likert scale takes some effort.
A Likert scale uses a number of Likert items, which are statements to which a respondent expresses his agreement or disagreement. Generally, a five-point or seven-point scale is used, for instance:
|
Strongly agree |
Agree |
Neutral |
Disagree |
Strongly disagree |
As you can see, each item is bipolar: it measures either someone's agreement or disagreement to the statement and allows you to give some measure of how much you agree or disagree. There are a variety possible response scales (1-to-7, 1-to-9, 0-to-4). All of these odd-numbered scales have a middle value is often labelled Neutral or Undecided. It is also possible to use a forced-choice response scale with an even number of responses and no middle neutral or undecided choice. In this situation, the respondent is forced to decide whether they lean more towards the agree or disagree end of the scale for each item.
The basic steps of developing a Likert scale are:
- Determine the focus: what concept are you going to measure (see what people's attitudes are toward it)?
- Ask a group of people (or a person) to write down different statements about this concept, reflecting different opinions or attitudes about the subject. Make sure you have a large number of statements, making sure that people can express their degree of agreement or disagreement on a five or seven-point scale.
- Rating the scale items: the next step is to have your group rate each statement on your five-point (or seven-point, or 10-point) scale in terms of how much each statement indicates a favourable or unfavourable attitude towards the concept. The members of the group must not express their own opinion, they must only indicate how favourable or unfavourable they feel each statement is. All statements (Likert items) in the Likert scale must use the same number of points on the scale (so either a 5-point scale, or a 7-point scale, but not a mix of the two).
- Select the items for the actual scale: The next step is to compute the intercorrelations between all pairs of items, based on the ratings of the judges. In making judgements about which items to retain for the final scale there are several analyses you can:
- Throw out any items that have a low correlation with the total (summed) score across all items
- For each item, get the average rating for the top quarter of judges and the bottom quarter. Then, do a t-test of the differences between the mean value for the item for the top and bottom quarter judges.
Correlation between the items and the total score: In most statistics packages it is relatively easy to compute this type of Item-Total correlation. First, you create a new variable which is the sum of all of the individual items for each respondent. Then, you include this variable in the correlation matrix computation (if you include it as the last variable in the list, the resulting Item-Total correlations will all be the last line of the correlation matrix and will be easy to spot). How low should the correlation be for you to throw out the item? There is no fixed rule here -- you might eliminate all items with a correlation with the total score less that .6, for example.
T-test: Higher t-values mean that there is a greater difference between the highest and lowest judges. In more practical terms, items with higher t-values are better discriminators, so you want to keep these items. In the end, you will have to use your judgement about which items are most sensibly retained. You want a relatively small number of items on your final scale (e.g., 10-15) and you want them to have high Item-Total correlations and high discrimination (e.g., high t-values).
For a detailed example, see http://www.socialresearchmethods.net/kb/scallik.php
You can now use the scale to measure attitudes 'in the field': enter the list of statements and use them to interview people or present them in a document. For each item, they should express to what degree they agree or disagree. The final score for the respondent on the scale is the sum of their ratings for all of the items (this is why this is sometimes called a summative scale). On some scales, you will have items that are reversed in meaning from the overall direction of the scale. These are called reversal items. You will need to reverse the response value for each of these items before summing for the total. That is, if the respondent gave a 1, you make it a 5; if they gave a 2 you make it a 4; 3 = 3; 4 = 2; and, 5 = 1.
Working with classes
Modifying the class names (column headers)
When you set the Question type to 'Summative scale (Likert)', you will get an empty table with the 'Labels' column on the left, and by default five classes:

To change the column headers, click somewhere in the column, and then on the button. You can also double-click on the column header itself. This will make a text field appear, where you can modify the header of this column.
Adding and removing classes
If you want to add a class (column), click in the column to the right of where you want to insert it. Then press the button in the toolbar.
If you want to remove a class (column), click in the column itself and then on the button.
Add statements
To add the statements that make up your scale, go to the first row and enter them in the 'Label' column.
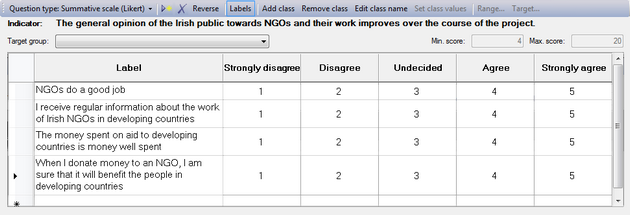
Reversing the scores/values
Logframer will number the cells of the scale from 1 to the number of columns/classes. For instance, when you have a five-item scale, the cells will be numbered from 1 to 5. You can use these numbers to count how many people have made a particular choice. Or you can use the values as scores, and calculate how well your project has done in comparison to a situation where all the beneficiaries have the maximum or minimum score (depending on whether the preferential choice is 1 or 5). The maximum and minimum scores are indicated on the right, above the table.
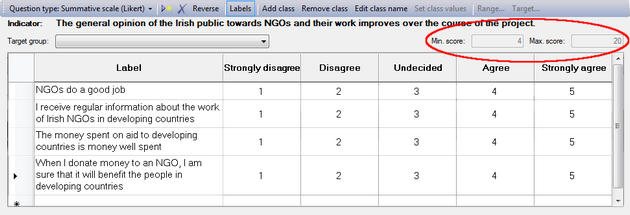
If you want to reverse the order of these scores, you can click on the 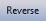 button. Instead of 1-2-3-4-5, you will get 5-4-3-2-1.
button. Instead of 1-2-3-4-5, you will get 5-4-3-2-1.
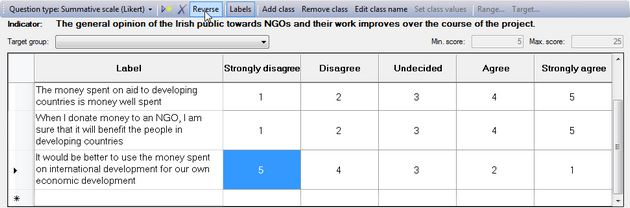
Modifying the values of the favourable answers
If you want to change the values that are automatically inserted when you add a new statement, just click on the cell and type any other value for your scale.
Cumulative scale (Guttman scale)
The cumulative scale or Guttman scale measures to what degree a person has a positive or negative attitude to something. It makes use of a series of statements that are growing or descending in how positive or negative a person is towards the subject. If for instance on a scale with seven statements the respondent agrees with the fifth statement, it implies that he or she also agrees with the first four statements, but not with statement number six and seven.
To create a Guttman scale, you need to:
- Determine the focus: what concept are you going to measure (see what people's attitudes are toward it)?
- Ask a group of people (or a person) to write down different statements about this concept, reflecting different opinions or attitudes about the subject. Make sure you have a large number of statements, making sure that people can either degree or disagree with them (no - open - questions for instance).
- Rating the scale items: the next step is to have your judges rate each statement, indicating whether the statement expresses a positive (favourable) or negative (unfavourable) attitude towards the concept. The members of the group must not express their own opinion about the concept, they must only indicate whether the statement is favourable or unfavourable.
- Developing the scale: construct a matrix or table that shows the responses of all the respondents on all of the items. Then sort this matrix so that respondents who agree with more statements are listed at the top and those agreeing with fewer are at the bottom. For respondents with the same number of agreements, sort the statements from left to right from those that most agreed to those that fewest agreed to.
- If there are lots of items, you need to use a data analysis called scalogram analysis to determine the subsets of items from our pool that best approximate the cumulative property. Then review these items and select the final scale elements. There are several statistical techniques for examining the table to find a cumulative scale.
- Because there is seldom a perfectly cumulative scale you usually have to test how good it is. These statistics also estimate a scale score value for each item. This scale score is used in the final calculation of a respondent's score.
For a detailed example, see http://www.socialresearchmethods.net/kb/scalgutt.php
You can now use the scale to measure attitudes 'in the field': enter the list of statements and use them to interview people or present them in a document. For each item, they should express whether they agree or disagree. Each scale item has a scale value associated with it (obtained from the scalogram analysis). To compute a respondent's scale score we simply sum the scale values of every item they agree with.
Modifying the class names (column headers)
When you set the Question type to 'Cumulative scale (Guttman)', you will get an empty table with the usual 'Labels' column, and two classes: 'Agree' and 'Disagree'. You can change the headers of these columns any way you want, but make sure that the second column remains the favourable option and the last column the unfavourable option.
To change the column headers, click somewhere in the column, and then on the button. You can also double-click on the column header itself. This will make a text field appear, where you can modify the header of this column.
Add statements
To add the statements that make up your scale, go to the first row and enter them in the 'Label' column.
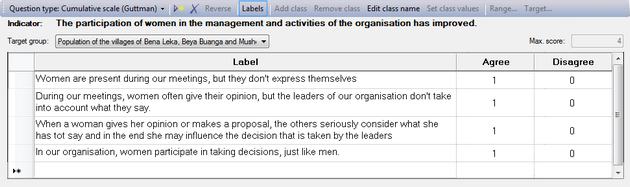
Every time you add a statement, you will see a '1' appear in the 'Agree' column (second column). If you want, you can modify this score but you can only modify the value in the 'Agree' column and not in the 'Disagree' column.
Semantic differential
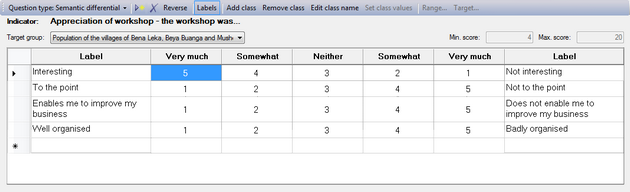
A semantic differential is useful to measure what the attitude is of the respondent towards something. In a semantic differential, you have two opposing characteristics at either end of a scale (also called a bipolar pair). This scale in the middle typically has five or seven items. When the number of items on the scale is uneven, the middle one expresses a neutral point between the two extremes. But this is not necessarily so, you can also have a scale with an even number of items - sometimes up to ten items are used in the scale.
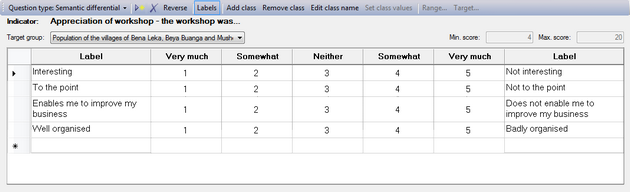
Working with classes
Modifying the class names (column headers)
When you select 'Semantic differential' as the Question type, you will get an empty table with two label columns at either end, and a five-item scale in the middle:
|
Very much |
Somewhat |
Neither |
Somewhat |
Very much |
To change these column headers, just click somewhere in the column, and then on the button. You can also double-click on the column header. This will make a text field appear, where you can modify the name of this class (column).
Adding and removing classes
If you want to add a class (column), click in the column to the right of where you want to insert it. Then press the button in the toolbar.
If you want to remove a class (column), click in the column itself and then on the button.
Adding pairs and changing scores
Adding bipolar pairs
To add questions, go to the first row and enter the pairs in the 'Label' columns at the left and right of the table. The easiest way to come up with a bipolar pair is to write a word or concept in the first column, and to copy it in the last column and put 'not' in front.
Reversing the scores/values
Logframer will number the cells of the scale from 1 to the number of columns/classes. For instance, when you have a five-item scale, the cells will be numbered from 1 to 5. You can use these numbers to count how many people have chosen a particular column. Or you can use the values as scores, and calculate how well your project has done in comparison to a situation where all the beneficiaries have the maximum or minimum score (depending on whether the preferential choice is 1 or 5). The maximum and minimum scores are indicated on the right, above the table.
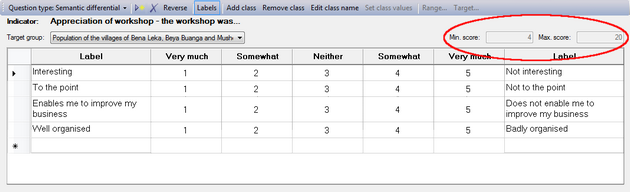
If you want to reverse the order of these scores, you can click on the button. Instead of 1-2-3-4-5, you will get 5-4-3-2-1.